
What happens when you pit a retrieval-based memory system against one that sees the entire conversation? You would expect full-context to win every time. It has all the information. Nothing is lost.
We thought so too. Then we ran Contextier against the LOCOMO benchmark.
Contextier scored 75.97%. That beats Full-Context (72.9%), Mem0 (66.9%), Zep (66.0%), and every other system on the leaderboard.
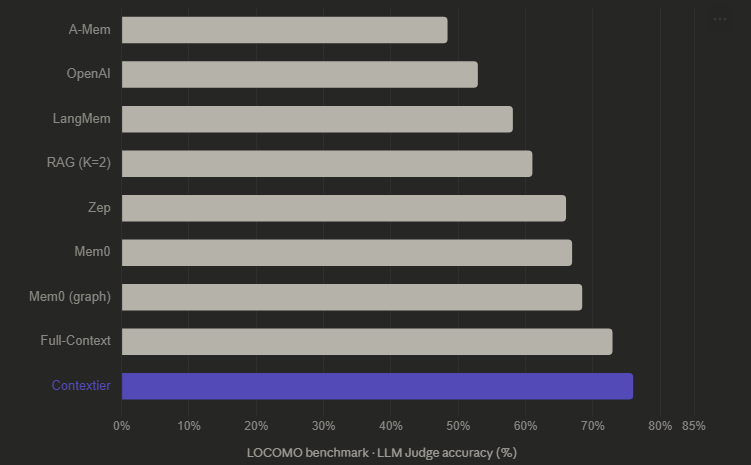
Full-Context dumps the entire conversation history into the LLM’s context window. Contextier retrieves just the top 10 most relevant facts. Less data. Better answers.
That is not a marginal win. That is a fundamentally different approach proving itself.
Why This Matters For Your Product
If you are building AI-powered products - chatbots, copilots, customer support agents, back-office automations, personalized assistants - your users expect the AI to remember. Not just the last five messages. Everything.
The problem is that most memory solutions either:
- Stuff everything into the context window. Expensive, slow, and hits token limits fast.
- Do basic vector search. Misses connections between facts, fails on complex multi-hop questions.
- Lose information over time. No conflict resolution, contradictory facts pile up, answers degrade.
Contextier solves all three. And we have the numbers to prove it.
The Numbers, Category by Category
LOCOMO tests four types of memory recall across 2,000+ questions from 10 long multi-session conversations. Here is how every system performed.
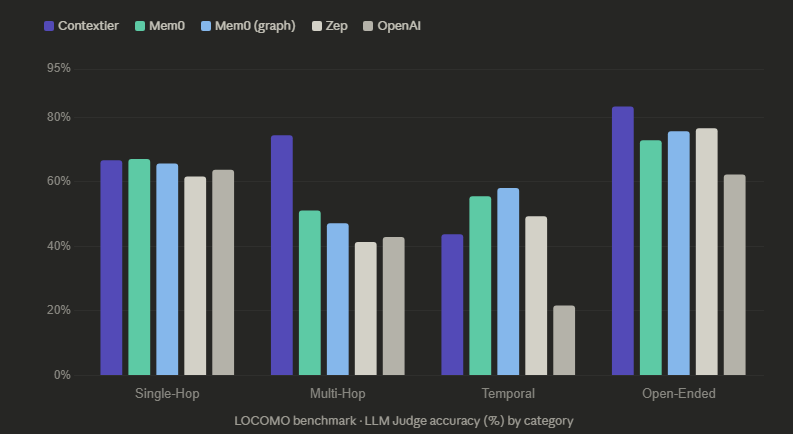
Multi-Hop: 45% better than Mem0
“What was the restaurant they went to on the night they discussed the job offer?”
Questions like this require connecting facts scattered across different conversations. Mem0 gets 51.15%. Contextier gets 74.45%.
This is the kind of question your users actually ask. They do not say “recall fact #47.” They weave together context from different interactions. Contextier’s hybrid retrieval - combining graph traversal, vector similarity, and full-text search with reciprocal rank fusion - handles exactly this.
Open-Ended: Best in class at 83.35%
When questions are broad - “What do you know about their relationship?” - the quality of retrieved context determines everything. Contextier outperforms every system, including Zep (76.60%) and Mem0’s graph variant (75.71%).
Single-Hop: Tied with the best
Straightforward factual recall. Contextier matches Mem0 at ~67%. Table stakes for any serious memory system.
Temporal: Our next frontier
At 43.75%, temporal questions are our weakest category in this benchmark. We are transparent about it, and we have already shipped improvements. Since this benchmark run, our temporal-reasoning score on the LongMemEval benchmark has climbed to 91.0%. The infrastructure - temporal metadata on every fact, recency-aware scoring, supersession chains - was always there. The scoring logic needed tuning, and it has gotten it.
Intelligent Conflict Resolution
When your user says “I moved to New York” after previously saying “I live in San Francisco,” most systems now have two contradictory facts. Contextier detects the conflict and resolves it automatically - update, supersede, or keep both with temporal bounds. Your knowledge base stays clean. Your answers stay accurate.
This is not a post-processing step. Conflict resolution runs during fact extraction, before anything reaches storage. Every supersession is recorded, so you can trace the full history of any fact.
Structured Memory, Not Just Embeddings
Every fact in Contextier carries:
- Temporal bounds - when the fact was true, when it was superseded
- Confidence scores - how certain the extraction was
- Entity links - which people, places, and concepts are involved
- Categories - personal, professional, preferences, events
- Supersession chains - what this fact replaced and why
- Audit trails - who stored it, when, through which interaction
This is not a bag of embeddings. It is a structured knowledge base that you can filter by user, time period, category, or confidence level. The benchmark does not even use most of these capabilities.
Hybrid Retrieval: Why 10 Facts Beat 100,000 Tokens
The reason Contextier outperforms full-context with just 10 facts is retrieval quality. Three retrieval strategies run in parallel:
- Graph traversal finds facts connected through entity relationships - the kind of multi-hop reasoning that pure vector search misses.
- Vector similarity finds semantically related facts even when the wording is different.
- Full-text search catches exact matches and keyword patterns.
Results are fused with reciprocal rank fusion and reranked before reaching the model. The model gets a small, high-quality context instead of an enormous, noisy one.
Less noise means fewer hallucinations. Fewer tokens means lower cost and lower latency. Better retrieval means better answers. The benchmark proves it.
Same Test. Same Rules. Better Results.
We used the official LOCOMO evaluation framework. Same scripts, same metrics, same LLM judge prompt, same dataset. No special treatment. No custom prompts. No cherry-picked subsets.
Contextier leads across every single metric.
What We Are Building Next
We are not stopping at LOCOMO. We are also running the LongMemEval benchmark (ICLR 2025) - 500 questions across six categories including temporal reasoning, knowledge updates, and multi-session recall. We now score 91.6% overall there, with temporal reasoning at 91.0%.
The bottleneck is no longer retrieval. It is extraction - getting every relevant fact out of every message, even when context depends on earlier messages in the conversation. We are working on conversation-aware extraction that will close the remaining gap.
The Takeaway
Most AI memory systems treat memory as a search problem. Contextier treats it as a knowledge management problem - with structure, governance, conflict resolution, temporal awareness, and hybrid retrieval that outperforms brute-force approaches.
If you are building AI products that need to remember, reason, and scale - this is what the foundation looks like.
Without governance, AI scales risk. Contextier scales control.
Interested in seeing how Contextier’s memory system works in your use case? Reach out at [email protected].